Sesión 4 Lectura de datos
Para leer datos lo más sencillo es utilizar la interfaz de RStudio. En el caso de un archivo de texto plano (.csv, .txt,…) utilizaremos Environment > Import Dataset > From text (readr). Y seleccionamos los datos que queremos importar en la ventana.
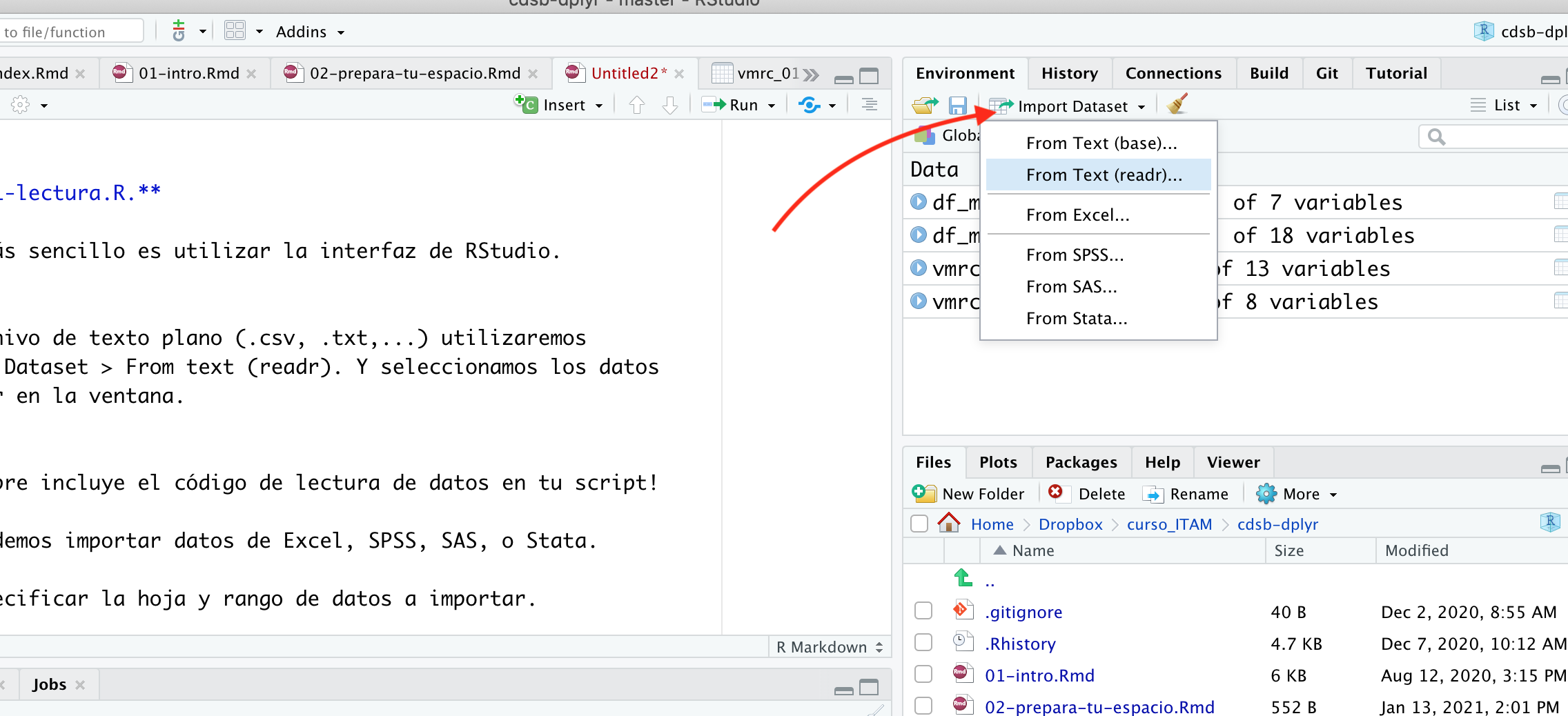
Importante: Siempre incluye el código de lectura de datos en tu script!
library(readr)
df_muni <- read_csv("datos/df_municipios.csv")
#> Rows: 2457 Columns: 8
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> chr (3): state_abbr, municipio_name, metro_area
#> dbl (5): pop, pop_male, pop_female, afromexican, indigenous
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
df_muni
#> # A tibble: 2,457 × 8
#> state_abbr municipio_name pop pop_m…¹ pop_f…² afrom…³ indig…⁴ metro…⁵
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
#> 1 AGS Aguascalientes 877190 425731 451459 532 104125 Aguasc…
#> 2 AGS Asientos 46464 22745 23719 3 1691 <NA>
#> 3 AGS Calvillo 56048 27298 28750 10 7358 <NA>
#> 4 AGS Cosío 15577 7552 8025 0 2213 <NA>
#> 5 AGS Jesús María 120405 60135 60270 32 8679 Aguasc…
#> 6 AGS Pabellón de Arteaga 46473 22490 23983 3 6232 <NA>
#> 7 AGS Rincón de Romos 53866 26693 27173 13 6714 <NA>
#> 8 AGS San José de Gracia 8896 4276 4620 13 1733 <NA>
#> 9 AGS Tepezalá 20926 10197 10729 4 3468 <NA>
#> 10 AGS El Llano 20245 9982 10263 0 936 <NA>
#> # … with 2,447 more rows, and abbreviated variable names ¹pop_male,
#> # ²pop_female, ³afromexican, ⁴indigenous, ⁵metro_area
#> # ℹ Use `print(n = ...)` to see more rows Abre el script ejercicios.R y añade código para leer los datos de
educación a nivel municipal, ubicados en la carpeta df_edu.csv.
Abre el script ejercicios.R y añade código para leer los datos de
educación a nivel municipal, ubicados en la carpeta df_edu.csv.
Usando la interfaz de RStudio también podemos importar datos de Excel, SPSS, SAS, o Stata. En Excel podemos especificar la hoja y rango de datos a importar.
library(readxl)
women_school <- read_excel("datos/Years_in_school_women_25_plus.xlsx",
sheet = "Data")
women_school
#> # A tibble: 175 × 41
#> `Row Labels` 1970.…¹ 1971.…² 1972.…³ 1973.…⁴ 1974.…⁵ 1975.…⁶ 1976.…⁷ 1977.…⁸
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Afghanistan 0 0.1 0.1 0.1 0.1 0.1 0.1 0.1
#> 2 Albania 3.9 4 4.1 4.2 4.3 4.5 4.6 4.7
#> 3 Algeria 0.6 0.6 0.6 0.7 0.7 0.8 0.8 0.9
#> 4 Angola 0.5 0.5 0.5 0.5 0.6 0.6 0.6 0.7
#> 5 Antigua and … 7 7.1 7.2 7.4 7.5 7.7 7.8 8
#> 6 Argentina 5.5 5.6 5.7 5.9 6 6.1 6.2 6.3
#> 7 Armenia 5.9 6 6.2 6.3 6.5 6.6 6.8 6.9
#> 8 Australia 8.4 8.5 8.6 8.7 8.8 8.9 9 9.1
#> 9 Austria 7.2 7.3 7.4 7.5 7.6 7.7 7.9 8
#> 10 Azerbaijan 4.5 4.6 4.8 5 5.1 5.3 5.5 5.7
#> # … with 165 more rows, 32 more variables: `1978.0` <dbl>, `1979.0` <dbl>,
#> # `1980.0` <dbl>, `1981.0` <dbl>, `1982.0` <dbl>, `1983.0` <dbl>,
#> # `1984.0` <dbl>, `1985.0` <dbl>, `1986.0` <dbl>, `1987.0` <dbl>,
#> # `1988.0` <dbl>, `1989.0` <dbl>, `1990.0` <dbl>, `1991.0` <dbl>,
#> # `1992.0` <dbl>, `1993.0` <dbl>, `1994.0` <dbl>, `1995.0` <dbl>,
#> # `1996.0` <dbl>, `1997.0` <dbl>, `1998.0` <dbl>, `1999.0` <dbl>,
#> # `2000.0` <dbl>, `2001.0` <dbl>, `2002.0` <dbl>, `2003.0` <dbl>, …
#> # ℹ Use `print(n = ...)` to see more rows, and `colnames()` to see all variable names