Sesión 8 Flujo de trabajo para Data Science
En esta parte hablaremos de flujos de trabajo para análisis de datos. Recordemos el diagrama del flujo de un análisis de datos:
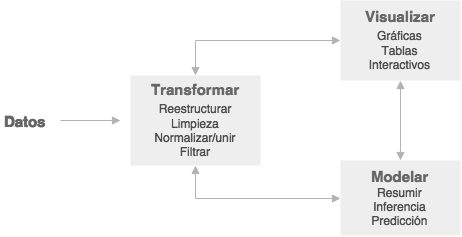
Quizá añadiendo que en este flujo una parte importante del trabajo es comunicar los resultados y hallazgos de este ciclo.
El flujo de trabajo son las operaciones que hacemos para obtener los resultados intermedios y finales de nuestro análisis (datos limpios, ajuste de un modelo, gráficas, reportes, etc.) Ningún flujo de trabajo es perfecto, pero quisiéramos promover aspectos como:
- Reproducibilidad: es posible reproducir las salidas de nuestro análisis de manera relativamente simple.
- Eficiencia: buscamos que nuestro flujo promueva pensar más en nuestro análisis que en detalles y complicaciones de cómo producimos ese análisis.
- Colaboración: es relativamente fácil que varias personas colaboren en un proyecto.
Proyectos
Como se explica en H. Wickham (2019), usuarios nuevos de R a veces consideran como “real” el ambiente de trabajo y los objetos que están ahí. Por eso muchas veces intentan preservar el estado del ambiente en R, guardando los objetos que están en memoria en un punto dado para recrear salidas o análisis. Pero a la larga, es mejor pensar que lo que es “real” en nuestro análisis son los scripts que producen esos objetos y salidas.
En términos de reproducibilidad y colaboración, guardar colecciones grandes de objectos que son salidas no es muy buena idea. Es difícil colaborar y reproducir resultados compartiendo objectos grandes que no sabemos exactamente cómo se crearon y que no tienen historial de cambios, o peor aún, que su construcción requiere de algunos comandos que no incluímos en scripts.
Es mejor pensar que lo “real” son los scripts (el código) que generan las salidas. Esto es lo que queremos preservar, compartir, y dar seguimiento conforme nuestro análisis avanza.
Tip: en las preferencias de RStudio, cambia si es necesario a nunca guardar el ambiente de trabajo en .RData, y nunca cargar al inicio archivos .RData (en el menú Tools -> Global Options).
Todos el código de nuestro proyecto generalmente lo organizamos bajo una misma carpeta, y comenzamos a trabajar en cada proyecto poniendo nuestro directorio de trabajo en esa carpeta. Las referencias a nuestros archivos se hacen a partir de ese directorio de trabajo.
Discusión
En R existen getwd()y setwd() para leer y cambiar el directorio de trabajo (working directory). Podemos hacer:
getwd()
#> [1] "/Users/tereom/docs/r-analisis-datos"Y también podríamos hacer
setwd('/MiCompu/Documentos/trabajo/proyectos_divertidos/proyecto_z/')Pero veremos que típicamente no necesitamos usar estos comandos. La siguiente cita es tomada de esta explicación
If the first line of your R script is setwd(“C:\Users\jenny\path\that\only\I\have”) I will come into your office and SET YOUR COMPUTER ON FIRE 🔥. –Jenny Bryan
Proyectos de RStudio
Una alternativa que nos guía a buenas prácticas es usar los proyectos de RStudio.
Ejercicio: crear un proyecto desde cero
- Crea un nuevo proyecto en R (en File -> New Project). Asegúrate de ponerlo bajo control de versiones de git. Crea dos carpetas nuevas dentro de tu proyecto, por ejemplo salidas y graficas. Crea un script 1_graficar.R. En el script haz una gráfica con ggplot de algunos datos que estén disponibles en R, y que guarde la gráfica en graficas y guarda los datos que usaste en la carpeta salidas en formato csv. Haz también, en la consola View de tus datos.
- Crea otro proyecto en RStudio. Nota que la sesión comienza en blanco.
- Ahora regresa a tu proyecto anterior (puedes usar el menú File, o también el navegador de archivos y hacer click en el archivo miproyecto.Rproj. ¿Qué notas al regresar a tu proyecto anterior?
- Haz git commit de tu archivo 1_graficar.R. ¿Qué piensas de poner bajo control de versiones el contenido de salidas y graficas?
Ejercicio: crear un proyecto a partir de un repositorio
- Crea un nuevo proyecto en R, pero esta vez escoge crear a partir de un repositorio. Utiliza esta liga de github, por ejemplo: https://github.com/tereom/quickcountmx.git. Este es un paquete de R, por lo que tiene una estructura especial.
- Examina el código en la carpeta R. Haz un cambio en el archivo TODO y haz commit de tu nuevo archivo. Examina el historial de cambios para este repositorio.
- Cambia a tu proyecto original.
El flujo básico de trabajo cuando trabajamos con proyectos es:
- Empezamos con un ambiente limpio en R. Nótese que con la configuración de arriba, cada vez que abrimos un projecto comenzamos con un ambiente limpio en R
- Escribimos código (en unidades chicas), lo probamos. Si todo sale bien hacemos commit.
- Conforme trabajamos, es buena idea reiniciar la sesión de R (Session->Restart R) y correr nuestros scripts completos -quizá utilizando resultados intermedios para cómputos que toman mucho tiempo. De esta forma sabemos que los resultados no dependen de algún comando o manipulación que hayamos hecho de manera interactiva.
- La idea siempre trabajar desde la carpeta raíz del proyecto (no es necesario cambiar directorios para correr distintas cosas).
- Cuando usamos proyectos de esta forma, todas nuestras rutas son siempre relativas a la raíz de nuestro proyecto. Por ejemplo, para cargar los datos que guardamos en el csv hacemos:
read.csv('salidas/archivo.csv')Introducción a ProjectTemplate
Una herramienta útil para organizar el código y automatizar mucho del trabajo manual en proyectos de análisis de datos es ProjectTemplate. ProjectTemplate (según la liga anterior)
- Organiza los archivos del projecto.
- Carga automáticamente los paquetes necesarios.
- Carga los datos necesarios, originales y/o derivados.
- Corre preprocesamiento y limpieza de datos para obtener las salidas que se usan en análisis.
Instala el paquete ProjectTemplate con:
install.packages("ProjectTemplate")Vamos a seguir el tutorial de ProjectTemplate:
Crear un nuevo proyecto
Cambia a tu directorio home, o el directorio donde va estar la
carpeta de tu proyecto (tienes que usar Set As Working Directory en RStudio si es necesario, o setwd).
library('ProjectTemplate')
create.project('letras-ejercicio')- Ahora crea un nuevo proyecto de RStudio, esta vez a partir de un directorio existente letras-ejercicio.
Examina el contenido de la carpeta del nuevo proyecto. Cada carpeta tiene un nombre que se autoexplica.
- Haz commit de todas las carpetas.
Agregando datos
Crea un archivo en la carpeta data que se llame letras.url, con este contenido:
url: https://s3.amazonaws.com/ejercicio-pt/letters.csv
separator: ,Ahora corre:
load.project()
letrasY nota que load.project() automáticamente cargó los datos en memoria:
ProjectTemplate searches through the data directory for files. If a file has a name like NAME.EXTENSION with a recognized extension such as .csv or .sql, ProjectTemplate will automatically load the data described in that file into memory. Generally, the automatically loaded data set will end up in an R data frame called NAME that will be placed in R’s global environment. If you’re not sure if your data set will be automatically loaded by ProjectTemplate, you can check the full list of currently supported filetypes here.
Librerías
Examina el archivo config/global.dfc. Cambia load_libraries a TRUE. Puedes
cargar librerías adicionales en libraries (cambia a solo cargar
tidyverse, stringr y lubridate). Corre load.project() otra vez: verifica que ahora los paquetes seleccionados se cargan automáticamente.
- Usa el comando
?project.configpara explicación de los parámetros de configuración.
Data y Cache
Nota que hay una carpeta que se llama cache. Esta carpeta sirve para guardar pasos intermedios de nuestro análisis, especialmente cuando toman mucho tiempo. Por default, una versión de los datos cargados se guarda en formato RData, así que no es necesario bajar los datos o hacer de nuevo el query a la base de datos cada vez que arrancamos el proyecto.
- En control de versiones, generalmente no queremos hacer commit al repositorio del carpeta de archivos grandes de data, y generalmente no queremos poner cache bajo control de versiones.
- En nuestro caso, podemos poner nuestro archivo que describe la fuente de datos bajo control de versiones. En general, si los datos son chicos, y no preveemos muchos cambios, podemos hacer commit de data.
Preprocesamiento
Normalmente tenemos algunos pasos de preprocesamiento. Crea un archivo en la carpeta munge que se llame 02-agregar.R, por ejemplo. Agrega el siguiente código:
primera <- letras |>
group_by(FirstLetter) |>
count() |> arrange(desc(n))
segunda <- letras |>
group_by(SecondLetter) |>
count() |> arrange(desc(n))Ahora reinicia R. Vuelve a hacer load.project() y corre por ejemplo:
primeraY verifica que los agregados se calcularon automáticamente (todos los scripts de munge se corren en orden alfabético), y que no bajaste los datos letras otra vez, gracias al cache.
Puedes hacer cache de resultados intermedios. Por ejemplo, si el cálculo de los scripts de munge toma mucho tiempo, puedes poner:
cache('primera')
cache('segunda')Ahora puedes cambiar en config/global.dcf la línea de munging a
munging: FALSE para no hacer el preprocesamiento cada vez que cargues
el proyecto.
Nota: en control de versiones, típicamente no hacemos commits de la carpeta cache: esta es para agilizar el trabajo en nuestro ambiente local.
Scripts de análisis
Ahora crea dos archivos nuevos en el directorio raíz de tu proyecto, que puedes llamar: 1_graficas.R y 2_resumenes.R, por ejemplo.
dos_letras <- left_join(primera |> rename(letra = FirstLetter),
segunda |> rename(letra = SecondLetter),
by = "letra")
grafica <- ggplot(dos_letras, aes(x = n.x, y = n.y, label = letra)) +
geom_text() + xlab('Primera letra') +
ylab('Segunda letra') +
labs(title = 'Frecuencias')
ggsave(grafica, 'graphs/frecuencias.pdf')En el archivo resúmenes puedes poner por ejemplo:
resumen <- dos_letras |>
gather(orden, frecuencia, -letra) |>
group_by(orden) |>
summarise( min = min(frecuencia), max = max(frecuencia))
resumen
write_csv(resumen, 'reports/tabla_resumen.csv')Estos archivos podemos correrlos (bajo la convención de que hay que correrlos en orden alfabético) para producir los resultados del análisis.
Guías de estilo
Las guías de estilo para escribir código tienen como propósito:
- Facilitar leer y escribir código: hay claras malas prácticas que dificultan el trabajo y deben ser evitadas.
- Reducir la carga mental al colaborar en proyectos: mayor consistencia implica una cosa menos en la que tenemos que pensar.
Hay varias buenas opciones. Lo importante para un equipo es acordar un estilo. Dos predominantes son:
Recomendaciones generales
En Good enough practices in scientific computing se detallan recomendaciones generales para flujos de trabajo en análisis de datos:
- Administración de datos
- Guarda los datos originales crudos.
- Crea los datos que quisieras ver en el mundo.
- Crea datos amigables para hacer análisis.
- Registra todos los pasos usados para procesar los datos.
- Anticipa el uso de múltiples tablas, creando identificadores
- Software
- Comenta explicando el funcionamiento de scripts y funciones.
- Descompón problemas grandes en funciones.
- Elimina duplicación
- Busca paquetes/librerías que estén bien mantenidas
- Prueba paquetes/librerías antes de confiar en ellos
- Usa nombres con significado para funciones y variables
- Haz explícitas dependencias y requisitos para tu código.
- Evita comentar/descomentar secciones de código para controlar su funcionamiento.
- Crea ejemplos simples o datos para hacer pruebas
- Colaboración
- Usa TODOs compartidos para el projecto.
- Decide en estrategias de comunicación.
- Organización del proyecto
- Pon cada projecto en su propio directorio
- Agrega documentos de texto a un directorio de docs dentro el proyecto.
- Pon datos crudos y metadatos en un directorio de datos y archivos generados en carpetas de resultados.
- Usa carpetas como lib o bin apra scripts externos o programas compilados
- Nombra archivos para que reflejen su contenido o función.
- Control de cambios
- Respalda prácticamente todo lo que se creó por una persona en cuanto fue creado.
- Mantén chicos los cambios
- Comparte frecuentemente los cambios
- Crea y matén un checklist para colaborar en el proyecto.
- Usa control de versiones
- Manuscritos
- Crea manuscritos con herramientas que se puedan usar online, control de cambios, control de formato y administración de referencias.
- Crea manuscritos en texto plano para permitir control de cambios.
Cuadernos y Reportes
R Markdown es un framework para producir documentos y reportes dinámicos con facilidad y buena calidad.
Hay dos formas de trabajar con R Markdown:
- Cuadernos: similar a jupyter, están diseñados para correr de manera interactiva.
- Reportes: diseñados para compilar completos y producir reportes dinámicos.
Reportes
Crea un nuevo documento de RMarkdown (File -> New File -> R Markdown) y guárdalo con el nombre que quieras en la carpeta reports. Presiona el botón Knit. También puedes ir a la carpeta reports y ver la salida, que es un archivo html que puedes abrir con tu navegador.
Nota en primer lugar que el documento tienen tres tipos de bloques:
- El bloque inicial (donde están title y output). Estos son los metadatos que indican cómo producir el reporte
- Bloques de texto. Este es texto markdown (ver markdown, filosofía y básicos), que texto usual más un lenguaje para dar formatos básicos al texto, incluir listas, ligas, tablas, imágenes entre otras cosas.
- Bloques de código (se llaman chunks), que están rodeados de triples comas inversas. Su encabezado puede contener parámetros que definen cómo se evalúan y muestran los resultados.
Ejercicio
- Agrega algún código adicional
como
cor(cars)al primer chunk, por ejemplo. Vuelve a hacer knit y examina los resultados. - Sustituye la gráfica por una de ggplot2 (tienes que cargar el paquete ggplot2).
Usar con ProjectTemplate
Una observación importante es que cuando hacemos knit de un documento de Rmarkdown, el directorio base de ejecución del documento es donde está ubicado el archivo Rmd. Para usar con ProjectTemplate tenemos entonces dos opciones: poner los archivos Rmd en el directorio base del proyecto, o cambiar el directorio base de ejecución. Para hacer los segundo, podemos agregar un chunk como sigue:
```{r echo=FALSE}
knitr::opts_knit$set(root.dir = '..' )
```Ejercicio
Crea un nuevo archivo R Markdown. Agrega chunks para mostrar
alguna tabla o gráfica usando los datos procesados del projecto
de las letras. Recuerda que uno de tus primeros chunks debe cargar
la librería ProjectTemplate y correr load.project(). Averigua como
omitir las salidas de ProjectTemplate para que no aparezcan en tu
reporte final.
Cuadernos
Los cuadernos usan la misma estructura de archivo que los reportes, pero están hechos para trabajar de manera interactiva.
Crea un nuevo documento de RMarkdown (File -> New File -> R Notebook) y guárdalo en la carpeta reports. Muévete al primer chunk y selecciona Run -> Run Current Chunk (o presionado Cmd+Shift+Enter). Sustituye la gráfica por una de ggplot y vuelve a correr el chunk.
En este caso, nota que se crea un archivo .nb.hmtl, que incluye tanto el Rmd como la salida en html. Cuando abrimos un Rmd con formato de cuaderno, utiliza las salidas en el html para mostrar las salidas en la misma ventana del editor.
Otros recursos para aprender Rmarkdown: